I'm a PhD student at the Institute for Machine Learning at ETH Zürich, where I'm advised by Prof. Menna El-Assady at IVIA and Prof. Ryan Cotterell at Rycolab.
My research focuses on inference-time language model control, integrating methods from probabilistic inference and human-computer interaction.
I'm quite active in the GenLM research consortium, where we are building an open-source ecosystem for language model probabilistic programming.
Before that, I obtained a master's degree in data science from ETH Zürich, graduating with a thesis on controlled LLM code generation at IBM Research Europe (ZRL).
I got an outstanding reviewer award (top 8% of reviewers) at NeurIPS'25 🏆
I presented at the GenLM onsite event at MIT Department of Brain and Cognitive Sciences in Boston.
One paper accepted at IEEE VIS 2025 in Vienna — congratulations to the team!
Our paper Finding Needles in Document Haystacks: Augmenting Serendipitous Claim Retrieval Workflows was accepted at CHI 2025 in Yokohama, Japan — congratulations to the team!
Our paper A Design Space for Intelligent Dialogue Augmentation was accepted at ACM IUI 2025! I will be presenting it in Cagliari in March. Thanks to all co-authors!
The paper we wrote at IBM Research on API integration with LLMs was accepted at EMNLP 2024 (Industry Track) — thanks to all co-authors! My colleague Thomas Gschwind from IBM Research will be presenting it in Miami in November.
Our paper On Affine Homotopy between Language Encoders was accepted at NeurIPS 2024. I will be presenting it in Vancouver in December. Thanks to all co-authors!
We gave a tutorial about the representational capacity of neural language models at ACL 2024 in Bangkok. Check out our interactive tutorial webpage!
Two papers I co-authored were accepted at ACL 2024!
Started a PhD at ETH Zürich, co-advised by Prof. Menna El-Assady and Prof. Ryan Cotterell! 🎉
Together with Katya Mirylenka, we will give a talk at Zurich-NLP about our work at IBM Research, at the ETH AI Center. RSVP here!
Our paper on counterfactual sample generation was accepted at ACL. I will be presenting it in Toronto in a few days! Check out our blog post about the paper!
Publications
Understanding Large Language Model Behaviors through Interactive Counterfactual Generation and Analysis
Furui Cheng,
Vilém Zouhar,
Robin SM Chan,
Daniel Fürst,
Hendrik Strobelt,
Menna El-Assady
IEEE Transactions on Visualization and Computer Graphics (IEEE VIS'25) , 2025 | pdf
Abstract
Counterfactual examples are useful for exploring the decision boundaries of machine learning models and determining
feature attributions. How can we apply counterfactual-based methods to analyze and explain LLMs? We identify the following key
challenges. First, the generated textual counterfactuals should be meaningful and readable to users and thus can be mentally compared
to draw conclusions. Second, to make the solution scalable to long-form text, users should be equipped with tools to create batches of
counterfactuals from perturbations at various granularity levels and interactively analyze the results. In this paper, we tackle the above
challenges and contribute 1) a novel algorithm for generating batches of complete and meaningful textual counterfactuals by removing
and replacing text segments in different granularities, and 2) LLM Analyzer, an interactive visualization tool to help users understand
an LLM's behaviors by interactively inspecting and aggregating meaningful counterfactuals. We evaluate the proposed algorithm by
the grammatical correctness of its generated counterfactuals using 1,000 samples from medical, legal, finance, education, and news
datasets. In our experiments, 97.2% of the counterfactuals are grammatically correct. Through a use case, user studies, and feedback
from experts, we demonstrate the usefulness and usability of the proposed interactive visualization tool
Interactive Systems · Language Model Explainability
Finding Needles in Document Haystacks: Augmenting Serendipitous Claim Retrieval Workflows
Moritz Dück,
Steffen Holter,
Robin SM Chan,
Rita Sevastjanova,
Menna El-Assady
Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI), 2025 | pdf
Abstract
Preliminary exploration of vast text corpora for generating and validating hypotheses, typical in academic inquiry, requires flexible navigation and rapid validation of claims.
Navigating the corpus by titles, summaries, and abstracts might neglect information, whereas identifying the relevant context-specific claims through in-depth reading is unfeasible with rapidly increasing publication numbers.
Our paper identifies three typical user pathways for hypothesis exploration and operationalizes sentence-based retrieval combined with effective contextualization and provenance tracking in a unified workflow.
We contribute an interface that augments the previously laborious tasks of claim identification and consistency checking using NLP techniques while balancing user control and serendipity.
Use cases, expert interviews, and a user study with 10 participants demonstrate how the proposed workflow enables users to traverse literature corpora in novel and efficient ways.
For the evaluation, we instantiate the tool within two independent domains, providing novel insights into the analysis of political discourse and medical research.
Interactive Systems · Language Models
On Affine Homotopy between Language Encoders
Robin SM Chan,
Reda Boumasmoud,
Anej Svete,
Yuxin Ren,
Qipeng Guo,
Zhijing Jin,
Shauli Ravfogel,
Mrinmaya Sachan,
Bernhard Schölkopf,
Menna El-Assady,
Ryan Cotterell
Advances in Neural Information Processing 38 (NeurIPS), 2024 | pdf
Abstract
Pre-trained language encoders -- functions that represent text as vectors -- are an integral component of many NLP tasks.
We tackle a natural question in language encoder analysis: What does it mean for two encoders to be similar? We contend that
a faithful measure of similarity needs to be intrinsic, that is, task-independent, yet still be informative of extrinsic
similarity -- the performance on downstream tasks. It is common to consider two encoders similar if they are homotopic, i.e.,
if they can be aligned through some transformation. In this spirit, we study the properties of affine alignment of language
encoders and its implications on extrinsic similarity. We find that while affine alignment is fundamentally an asymmetric notion of
similarity, it is still informative of extrinsic similarity. We confirm this on datasets of natural language representations. Beyond
providing useful bounds on extrinsic similarity, affine intrinsic similarity also allows us to begin uncovering the structure of the
space of pre-trained encoders by defining an order over them.
Representational Similarity · Language Encoders
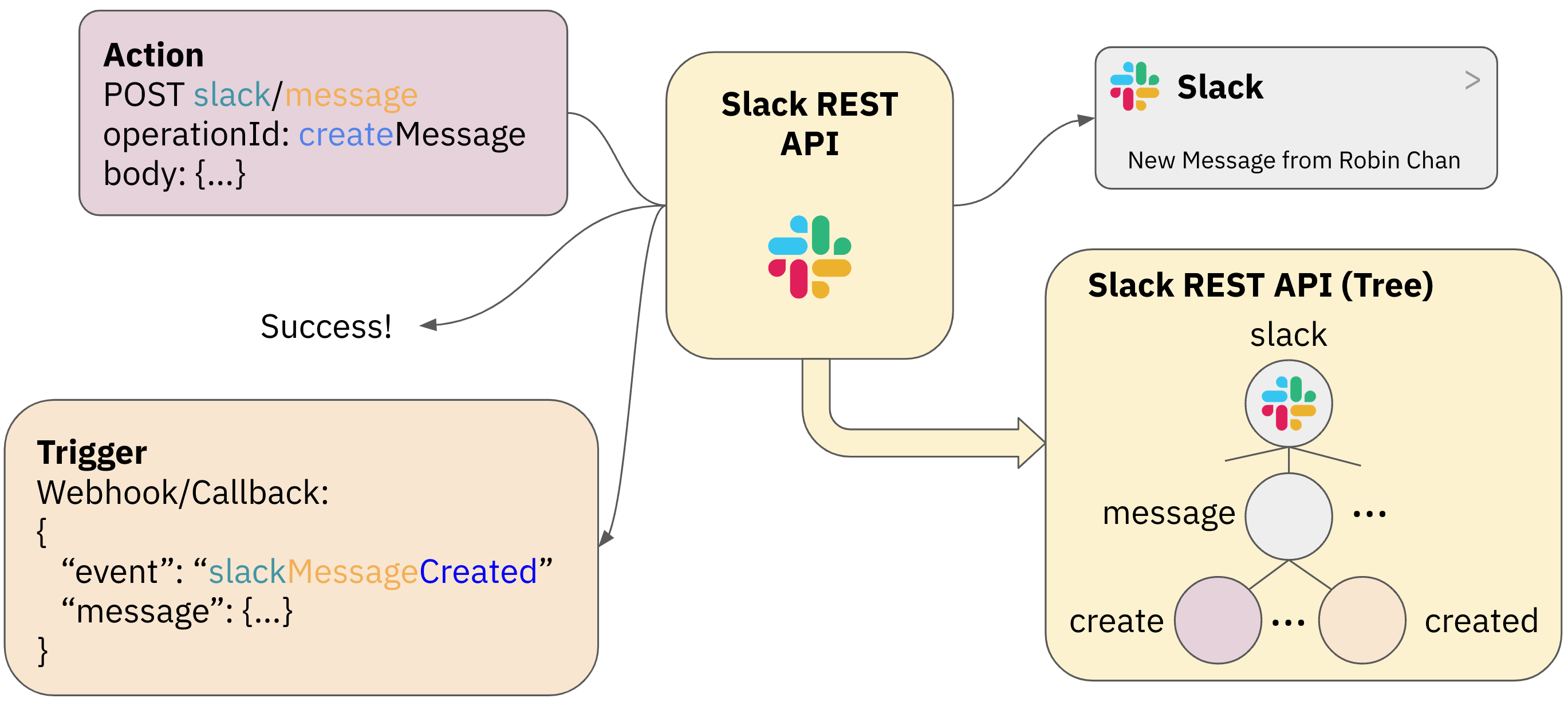
Adapting LLMs for Structured Natural Language API Integration
Robin SM Chan,
Katsiaryna Mirylenka,
Thomas Gschwind,
Christoph Miksovic-Czasch,
Paolo Scotton,
Enrico Toniato,
Abdel Labbi
Proceedings of EMNLP: Industry Track, 2024 | pdf
Abstract
Integrating APIs is crucial for enterprise systems, enabling seamless application interaction within workflows.
However, the vast and diverse API landscape makes combining calls based on user intent a significant challenge.
Existing methods rely on Named Entity Recognition (NER) and knowledge graphs, but struggle with control flow structures like
conditionals and loops. We propose a novel framework that leverages the success of Large Language Models (LLMs)
in code generation for natural language API integration. Our approach involves fine-tuning an LLM on automatically generated
API flows derived from services' OpenAPI specifications. This aims to surpass NER-based methods and compare the effectiveness
of different tuning strategies. Specifically, we investigate the impact of enforcing syntax through constrained generation or
retrieval-augmented generation. To facilitate systematic comparison, we introduce targeted test suites that assess the generalization
capabilities and ability of these approaches to retain structured knowledge. We expect to observe that fine-tuned LLMs can: (a) learn
structural constraints implicitly during training, and (b) achieve significant improvements in both in-distribution and out-of-distribution
performance.
Language Model Control · Parameter-Efficient Fine-Tuning
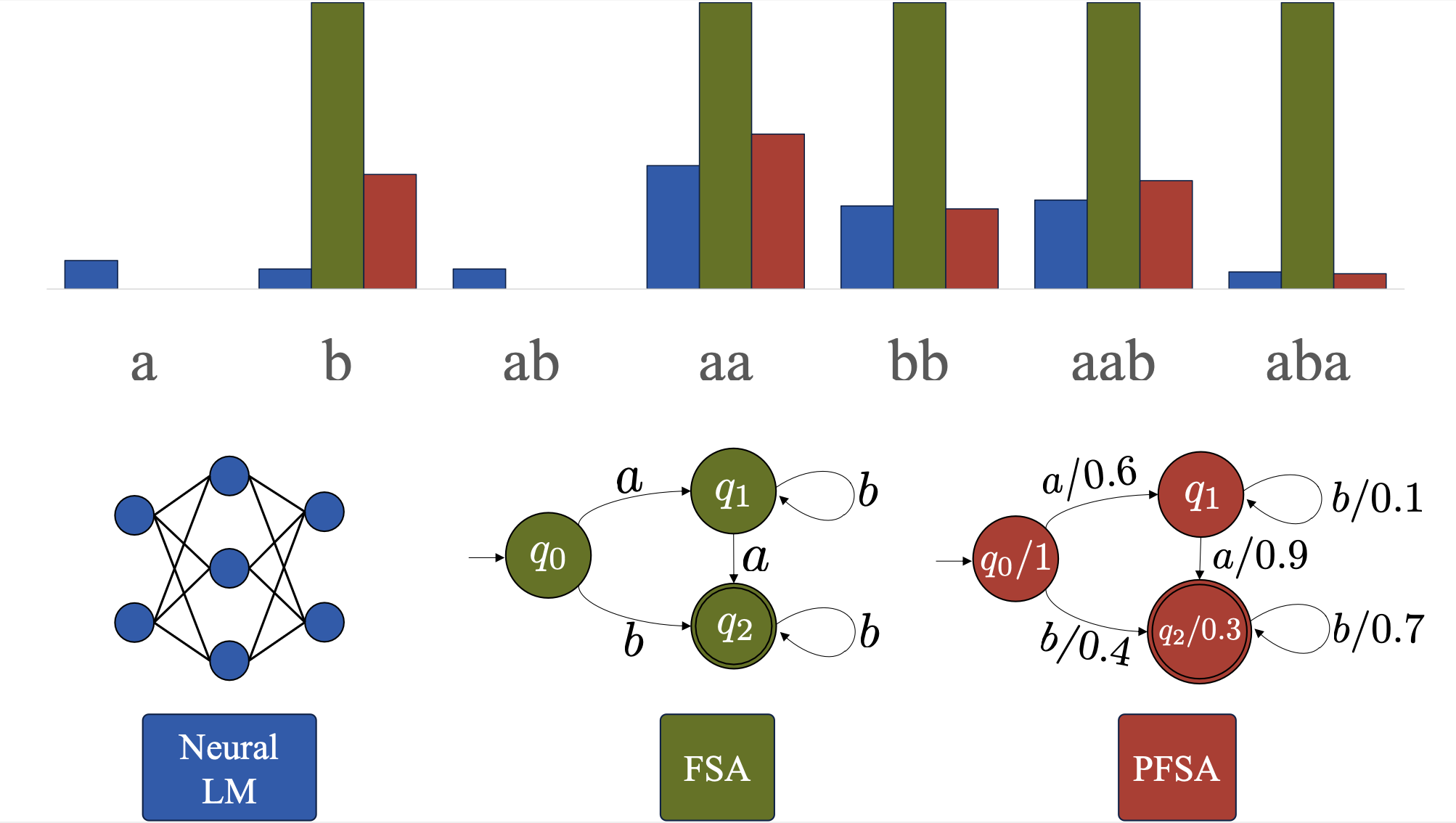
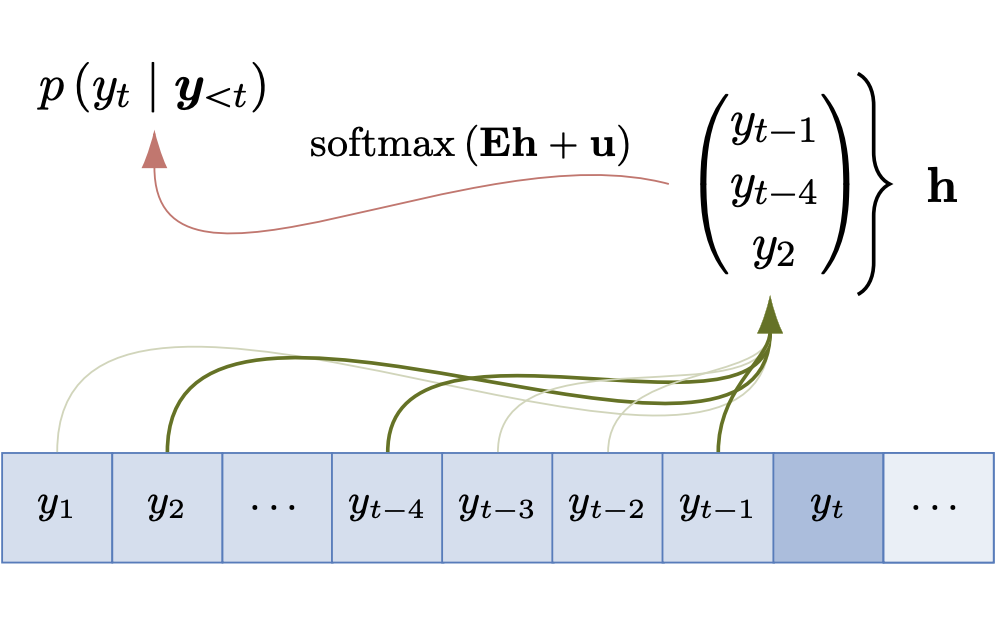
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Nadav Borenstein,
Anej Svete,
Robin SM Chan,
Josef Valvoda,
Franz Nowak,
Isabelle Augenstein,
Eleanor Chodroff,
Ryan Cotterell
Proceedings of ACL, 2024 |pdf
Abstract
What can large language models learn? By definition, language models (LM) are distributions
over strings. Therefore, an intuitive way of
addressing the above question is to formalize
it as a matter of learnability of classes of distributions over strings. While prior work in this
direction focused on assessing the theoretical
limits, in contrast, we seek to understand the
empirical learnability. Unlike prior empirical
work, we evaluate neural LMs on their home
turf—learning probabilistic languages—rather
than as classifiers of formal languages. In
particular, we investigate the learnability of
regular LMs (RLMs) by RNN and Transformer
LMs. We empirically test the learnability of
RLMs as a function of various complexity
parameters of the RLM and the hidden state
size of the neural LM. We find that the RLM
rank, which corresponds to the size of linear
space spanned by the logits of its conditional
distributions, and the expected length of
sampled strings are strong and significant
predictors of learnability for both RNNs and
Transformers. Several other predictors also
reach significance, but with differing patterns
between RNNs and Transformers.
Large Language Models · Formal Language Theory
On Efficiently Representing Regular Languages as RNNs
Anej Svete,
Robin SM Chan,
Ryan Cotterell
Findings of ACL, 2024 | pdf
Abstract
Recent work by Hewitt et al. (2020) provides
a possible interpretation of the empirical success of recurrent neural networks (RNNs) as
language models (LMs). It shows that RNNs
can efficiently represent bounded hierarchical structures that are prevalent in human language. This suggests that RNNs' success might
be linked to their ability to model hierarchy.
However, a closer inspection of Hewitt et al.'s (2020) construction shows that it is not limited to hierarchical LMs, posing the question
of what other classes of LMs can be efficiently
represented by RNNs. To this end, we generalize their construction to show that RNNs
can efficiently represent a larger class of LMs:
Those that can be represented by a pushdown
automaton with a bounded stack and a generalized stack update function. This is analogous
to an automaton that keeps a memory of a fixed
number of symbols and updates the memory
with a simple update mechanism. Altogether, the efficiency of representing this
diverse class of LMs with RNN LMs suggests
novel interpretations of their inductive bias.
Language Model Expressivity · Formal Language Theory
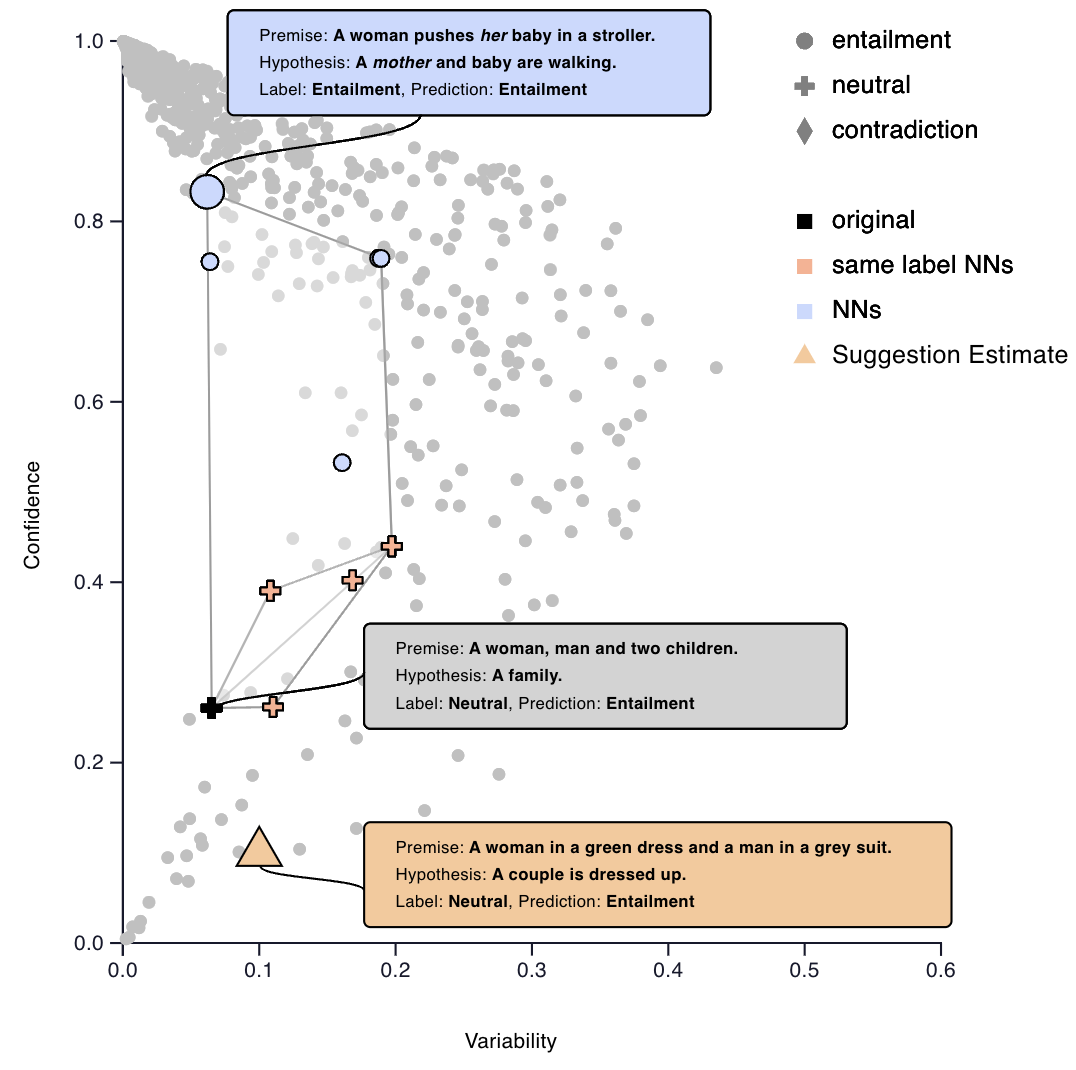
Which Spurious Correlations Impact Reasoning in NLI Models? A Visual Interactive Diagnosis through Data-Constrained Counterfactuals
Robin Chan,
Afra Amini,
Menna El-Assady
Proceedings of ACL: System Demonstrations, 2023 | pdf |
blog post
Abstract
We present a human-in-the-loop dashboard tailored to diagnosing potential spurious features that NLI models rely on for predictions.
The dashboard enables users to generate diverse and challenging examples by drawing inspiration from GPT-3 suggestions.
Additionally, users can receive feedback from a trained NLI model on how challenging the newly created example is and make refinements based on the feedback.
Through our investigation, we discover several categories of spurious correlations that impact the reasoning of NLI models, which we group into three categories:
Semantic Relevance, Logical Fallacies, and Bias. Based on our findings, we identify and describe various research opportunities, including diversifying
training data and assessing NLI models' robustness by creating adversarial test suites.
Counterfactuals · Mixed-Initiative Learning · Language Model Biases

{kind=link}